


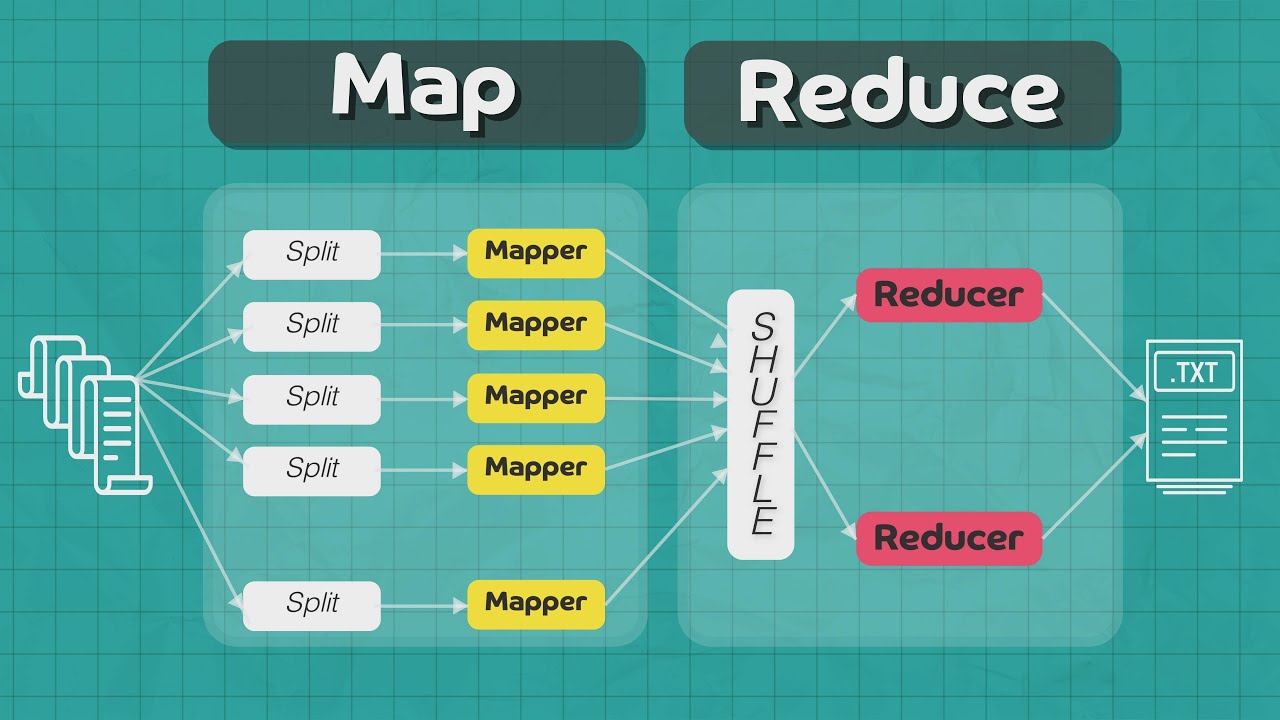
What is MapReduce? MapReduce is a programming model used for processing large data sets with a distributed algorithm on a cluster. Created by Google, it simplifies data processing across massive datasets by breaking tasks into smaller chunks. This model consists of two main functions: Map, which filters and sorts data, and Reduce, which performs a summary operation. Imagine having a giant library and needing to count the number of books by each author. Instead of one person doing all the work, you split the task among many people. Each person counts books by a specific author (Map), then all counts are combined (Reduce). This method makes handling big data more efficient and faster.
What is MapReduce?
MapReduce is a programming model used for processing large data sets with a distributed algorithm on a cluster. It simplifies data processing across massive clusters of computers.
-
MapReduce was developed by Google. It was introduced in a research paper by Jeffrey Dean and Sanjay Ghemawat in 2004.
-
The name "MapReduce" comes from two basic operations. "Map" applies a function to each item in a dataset, while "Reduce" aggregates the results.
-
Hadoop is the most popular implementation of MapReduce. Apache Hadoop is an open-source framework that allows for the distributed processing of large data sets using the MapReduce programming model.
-
MapReduce can handle petabytes of data. It is designed to process vast amounts of data efficiently.
-
MapReduce jobs are divided into tasks. Each job is split into smaller tasks that can be executed in parallel across a cluster.
How MapReduce Works
Understanding how MapReduce works can help grasp its power and efficiency in data processing.
-
The Map phase processes input data. Each input record is processed by a map function, which produces intermediate key-value pairs.
-
The Shuffle phase sorts and transfers data. Intermediate key-value pairs are sorted and transferred to the reduce phase.
-
The Reduce phase aggregates results. The reduce function processes each group of intermediate key-value pairs to produce the final output.
-
Fault tolerance is built-in. If a task fails, it is automatically retried on another node.
-
Data locality is optimized. MapReduce tries to run tasks on nodes where the data is already located, reducing data transfer times.
Benefits of Using MapReduce
MapReduce offers several advantages that make it a popular choice for big data processing.
-
Scalability is a key benefit. MapReduce can scale out to thousands of nodes in a cluster.
-
Cost-effectiveness is another advantage. Using commodity hardware reduces the cost of data processing.
-
Simplicity in programming. Developers can write simple code for complex data processing tasks.
-
High availability and reliability. Data is replicated across multiple nodes, ensuring availability even if some nodes fail.
-
Parallel processing boosts performance. Tasks are executed in parallel, speeding up data processing.
Real-World Applications of MapReduce
MapReduce is used in various industries to solve complex data processing problems.
-
Search engines use MapReduce. Google uses it to index the web and process search queries.
-
Social media platforms rely on it. Facebook and Twitter use MapReduce to analyze user data and trends.
-
E-commerce sites benefit from it. Amazon uses MapReduce for recommendation systems and customer data analysis.
-
Scientific research leverages it. Researchers use MapReduce to process large datasets in fields like genomics and astronomy.
-
Financial services utilize it. Banks and financial institutions use MapReduce for fraud detection and risk management.
Challenges and Limitations of MapReduce
Despite its benefits, MapReduce has some challenges and limitations.
-
Debugging can be difficult. Debugging distributed applications is more complex than single-node applications.
-
Not suitable for all types of data processing. MapReduce is not ideal for real-time processing or iterative algorithms.
-
High latency for small jobs. The overhead of setting up and managing tasks can lead to high latency for small jobs.
-
Complexity in managing clusters. Managing large clusters of nodes requires significant expertise and resources.
-
Limited support for advanced analytics. MapReduce is not well-suited for advanced analytics like machine learning.
Future of MapReduce
The future of MapReduce looks promising with ongoing developments and improvements.
-
Integration with other big data tools. MapReduce is being integrated with tools like Apache Spark for enhanced functionality.
-
Improvements in fault tolerance. New techniques are being developed to improve fault tolerance and reliability.
-
Enhanced performance optimizations. Researchers are working on optimizing performance for faster data processing.
-
Support for more programming languages. Efforts are underway to support more programming languages beyond Java.
-
Better resource management. Advances in resource management are making it easier to manage large clusters.
Fun Facts about MapReduce
Here are some interesting tidbits about MapReduce that you might not know.
-
MapReduce inspired other frameworks. Apache Spark and Apache Flink were inspired by the MapReduce model.
-
Used in the movie industry. Studios use MapReduce to process and render large amounts of video data.
-
MapReduce has a mascot. The Hadoop project, which implements MapReduce, has a yellow elephant as its mascot.
The Power of MapReduce
MapReduce has transformed how we handle big data. Its ability to process vast amounts of information quickly and efficiently makes it indispensable. By breaking down tasks into manageable chunks, it simplifies complex data operations. This approach not only saves time but also boosts productivity.
Scalability is another key benefit. Whether you're dealing with gigabytes or petabytes, MapReduce scales effortlessly. It’s designed to work seamlessly across distributed systems, ensuring reliability and fault tolerance.
Moreover, its open-source nature means continuous improvements and community support. Developers worldwide contribute to its evolution, making it more robust and versatile.
Understanding these facts about MapReduce can help you leverage its full potential. Whether you're a data scientist, engineer, or just curious about big data, knowing how MapReduce works can give you a significant edge. Embrace this powerful tool and watch your data processing capabilities soar.
Was this page helpful?
Our commitment to delivering trustworthy and engaging content is at the heart of what we do. Each fact on our site is contributed by real users like you, bringing a wealth of diverse insights and information. To ensure the highest standards of accuracy and reliability, our dedicated editors meticulously review each submission. This process guarantees that the facts we share are not only fascinating but also credible. Trust in our commitment to quality and authenticity as you explore and learn with us.