
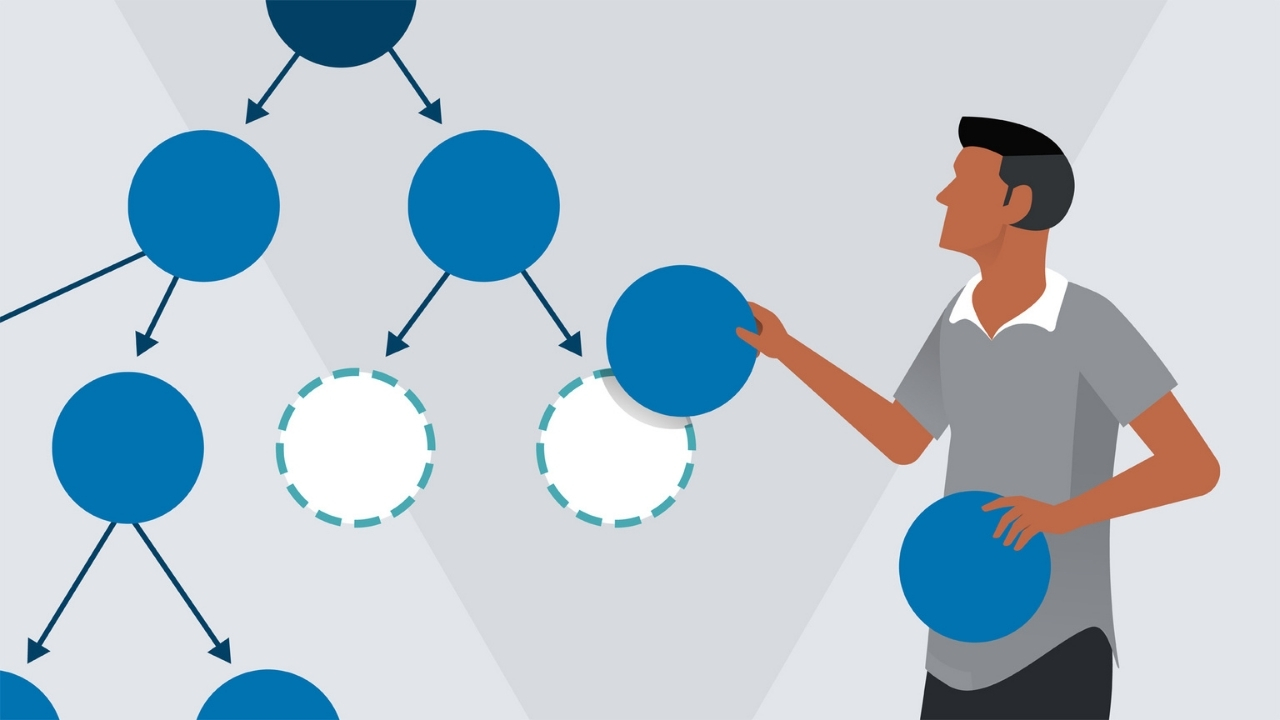
What is a tree data structure? A tree data structure is a way to organize data hierarchically. It consists of nodes connected by edges, resembling an upside-down tree. Why is it important? Trees are crucial in computer science for efficient data storage, retrieval, and manipulation. They power databases, file systems, and even search engines. How does it work? Each node contains data and links to its child nodes, starting from a root node. This structure allows quick access to data, making operations like searching, inserting, and deleting faster. Types of trees? Common types include binary trees, AVL trees, and B-trees. Each type has unique properties suited for different tasks. Want to learn more? Keep reading to uncover 27 fascinating facts about tree data structures!
What is a Tree Data Structure?
A tree data structure is a way to organize data hierarchically. It consists of nodes connected by edges, resembling a tree with branches. This structure is widely used in computer science for various applications.
- Nodes: The basic units of a tree. Each node contains data and may link to other nodes.
- Root: The topmost node in a tree. It serves as the starting point.
- Edges: Connections between nodes. They represent relationships.
- Leaf Nodes: Nodes without children. They are the endpoints.
- Internal Nodes: Nodes with at least one child. They act as intermediaries.
- Subtree: A smaller tree within a larger one. It consists of a node and its descendants.
Types of Tree Data Structures
Different types of trees serve various purposes. Each type has unique characteristics and uses.
- Binary Tree: Each node has at most two children. It's simple yet powerful.
- Binary Search Tree (BST): A binary tree where left children are smaller and right children are larger. It allows efficient searching.
- AVL Tree: A self-balancing BST. It maintains balance to ensure quick operations.
- Red-Black Tree: Another self-balancing BST. It uses color properties to maintain balance.
- B-Tree: A generalization of a BST. It can have more than two children, making it suitable for databases.
- Heap: A specialized tree for priority queues. It ensures the highest (or lowest) priority element is always at the root.
Applications of Tree Data Structures
Trees are versatile and find applications in many areas of computer science and beyond.
- File Systems: Organize files and directories. Each directory is a node with subdirectories and files as children.
- Databases: Use B-trees for indexing. They allow quick data retrieval.
- Compilers: Parse syntax trees. They represent the structure of source code.
- Artificial Intelligence: Use decision trees. They help in making decisions based on conditions.
- Networking: Use spanning trees. They ensure efficient routing and prevent loops.
- Games: Use game trees. They represent possible moves and outcomes.
Properties of Tree Data Structures
Understanding tree properties helps in designing and analyzing algorithms.
- Height: The length of the longest path from the root to a leaf. It affects the efficiency of operations.
- Depth: The length of the path from the root to a node. It varies for different nodes.
- Balanced Tree: A tree where the height difference between subtrees is minimal. It ensures efficient operations.
- Complete Tree: A tree where all levels are fully filled except possibly the last. It ensures compact storage.
- Full Tree: A tree where every node has 0 or 2 children. It has a specific structure.
- Perfect Tree: A tree where all internal nodes have two children and all leaves are at the same level. It is both full and complete.
Algorithms for Tree Data Structures
Various algorithms operate on trees to perform tasks like traversal, insertion, and deletion.
- Tree Traversal: Visiting all nodes in a specific order. Common methods include in-order, pre-order, and post-order traversal.
- Insertion: Adding a new node. The method depends on the tree type.
- Deletion: Removing a node. It may involve reorganization to maintain tree properties.
The Final Branch
Tree data structures are more than just a computer science concept. They’re essential for organizing data efficiently. From binary trees to AVL trees, each type has its unique strengths. Knowing these can help you choose the right one for your needs.
Understanding tree traversal methods like in-order, pre-order, and post-order can make data retrieval faster. Plus, recognizing the importance of balancing trees ensures your operations remain efficient.
Remember, trees aren't just theoretical. They’re used in databases, file systems, and even AI. So, next time you search for something online or navigate a file directory, thank tree data structures.
Keep exploring and applying these concepts. They’re foundational for anyone diving into computer science or software development. Happy coding!
Was this page helpful?
Our commitment to delivering trustworthy and engaging content is at the heart of what we do. Each fact on our site is contributed by real users like you, bringing a wealth of diverse insights and information. To ensure the highest standards of accuracy and reliability, our dedicated editors meticulously review each submission. This process guarantees that the facts we share are not only fascinating but also credible. Trust in our commitment to quality and authenticity as you explore and learn with us.